📚 The Vagueness of Vagueness in Noun Phrases
This vision and survey paper is part of the NoRDF project and is a joint work between Pierre-Henri Paris, Syrine El Aoud and Fabian Suchanek (Télécom Paris, DIG team).
For more details, you can check the full AKBC paper here.
TL;DR
- Vagueness is a very frequent phenomenon in texts since it is very useful to express something without being overspecific.
- Most knowledge bases do not allow to represent such knowledge.
- We study high quality Wikipedia articles: 26% of noun phrases are vague.
- We propose to classify knowledge according to 3 types:
- Scalar vagueness concerns expressions that can be ranged on a numerical scale, e.g., “tall” or “rich”.
- Quantitative vagueness concerns portions or undetermined quantities like “many scientists”.
- Subjective vagueness concerns vague expressions that can range over a scale for which there is no consensus.
- Vagueness detection and classification should not be a major problem since we achieved an accuracy of 0.78.
- Scalar and quantitative vagueness could be managed with great effort by merging several formalisms such as generalized quantifiers and fuzzy logic.
- Subjective vagueness could be partially addressed with annotations, but with very limited reasoning capabilities.
Table of Contents
- TL;DR
- Table of Contents
- What do we want to do?
- What is vagueness?
- The Wikipedia case
- Detecting vagueness
- Modeling and reasoning with vagueness
- What remains to be done
- Additional materials
- To cite this work
- Acknowledgments
What do we want to do?
Our goal is to explore how to deal with vagueness in knowledge bases. Indeed, vagueness is frequent in texts since we found that 26% of the noun phrases are vague in a Wikipedia corpus (see The Wikipedia case). This is logical since vagueness is often a necessary phenomenon to express something without being overspecific.
Let’s have a look at this example:
“An anti-tobacco sentiment grew in many nations from the middle of the 19th century.”
This sentence is factual, and is therefore an interesting candidate to be extracted and modeled in a knowledge base. However, in this sentence, all noun phrases are vague in some way:
- What is an “anti-tobacco sentiment”?
- How many nations are “many”?
- Which period is covered exactly by “the middle of the 19th century”? Is 1838 in this interval? Or 1853?
This type of information is rarely extracted from texts, and in any case most knowledge bases are unable to represent such information and thus a large amount of knowledge is lost.
Challenges
To deal with such sentences in knowledge bases, we face multiple challenges:
- How can we detect vague entities? Current information extraction approaches for KB construction often focus on named entities, and do not deal with phrases such as “anti-tobacco sentiments”.
- How can we model vague entities in a KB? Current large-scale KBs cannot make statements about sets of unknown size such as “many nations”.
- How can we reason on vague entities? If the sentiments grew in “many nations”, we can deduce that there were more than “in few nations”, but current KBs cannot do that type of reasoning.
What is vagueness?
Vagueness definition is a matter of philosophical disputes for a long time and the subject of several paradoxes, e.g., the paradox of the heap or the Loki’s wager. Taking inspiration from the vagueness doctrine in American constitutional law, we propose a first definition: a concept is vague if it would not be admissible in a law. Another possible definition, according to Alexopoulos and Pavlopoulos (2014), is that a concept is vague if it admits borderline cases.
However, what is really needed is a clear categorization, that is suitable for humans and machines. Several propositions of categorizations of vagueness exist, but none of them were satisfying when annotating (see following section). Hence, we propose three categories of vagueness.
Scalar vagueness
Scalar vagueness appears in expressions that can be interpreted as a scalar that ranges over a numerical scale and for which an unspecified threshold gives a truth value.
For example, in “Mary is a tall woman”, the height of Mary could range from 40 cm to 220 cm, and the assertion is true if Mary is taller than a certain implicit threshold (e.g., 180 cm).
Quantitative vagueness
Quantitative vagueness appears in expressions that refer to an unspecified portion of an entity, or to a set of entities whose number is not identified (as in “many scientists”, or just “scientists”). It applies generally to plural nouns without a definite article or cardinal, except if they refer to the concept itself.
For example, “a part of the film”, “many scientists”, or just “scientists” are quantitatively vague, while in “Apples are fruits” neither “apples” nor “fruits” are vague.
Subjective vagueness
Subjective vagueness appears in expressions that can apply to a certain degree, and where there is no consensus on how to measure this degree. These often carry a subjective valuation, and correspond to Walter Bryce Gallie’s “essentially contested concepts”.
For example, subjective vagueness applies to nouns such as “beauty” or “ingenuity”.
The Wikipedia case
We manually annotated a corpus of 30 abstracts of Wikipedia featured articles since they are quality articles and thus more likely to be a lower bound vagueness-wise.
With nltk, we extracted 2457 noun phrases, and for each of the noun phrases, we gave its vagueness type (not vague, scalar, quantitative and/or subjective). We also annotated each noun phrase with its plurality (plural vs. singular), its type of modifiers (adjectives, subordinate phrases, etc.), and its semantic class. Inspired by Yago 4, we used the top-level classes of schema.org combined with the top-level classes of BioSchemas.org, i.e. 11 classes in total.
The following table shows the proportions for each vagueness types:
| Vagueness | Number | Proportion | Examples |
|---|---|---|---|
| None | 1818 | 73.99% | “the company”, “three children”, “Paris”, … |
| Scalar | 148 | 6.03% | “long-running debate”, “early history”, “a large share”, … |
| Quantitative | 340 | 13.84% | “many of the ideas”, “government bodies”, “other media”, … |
| Subjective | 230 | 9.37% | “tensions”, “high ethical standards”, “sufficient interest”, … |
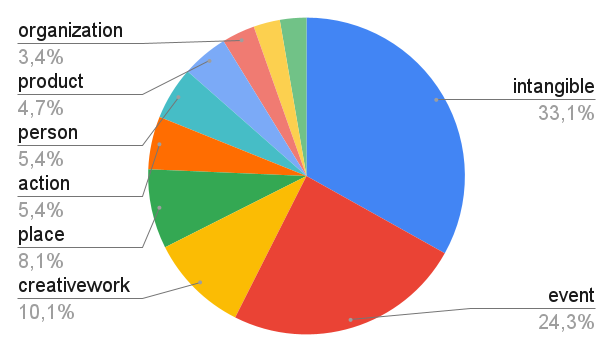
- 26% of noun phrases are vague.
- The most vague classes are in order:
- Intangible objects with many subjectively vague concepts such as beauty and ingenuity.
- A few taxon noun phrases are present, but a lot of them are (quantitatively) vague.
- 35% of all actions are vague because of subjective and quantitative vagueness.
- The classes of person, place, organization, and product are very frequent but rarely vague.
- Undetermined noun phrases are often vague (46%) because they often exhibit quantitative vagueness (as in “government bodies”).
- Noun phrases with an adjective are also very often (scalarly or subjectively) vague (45%).
- Mass nouns are also vague 29% of the time, and this is because they tend to be subjectively vague (as in “fame”).
- Determined noun phrases are less likely to be vague.
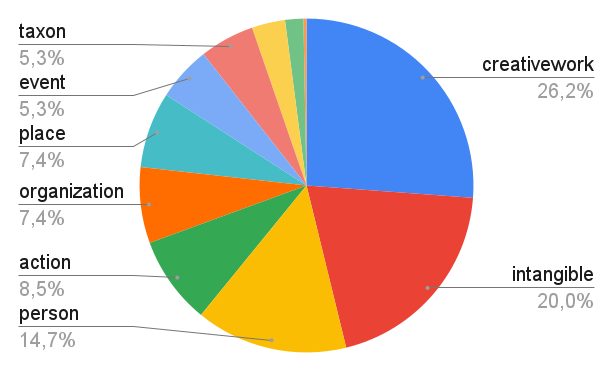
- Scalar vagueness is the least frequent vagueness type, with only 6%.
- Scalar vagueness is usually (in 66% of the scalar vague noun phrases) induced by an adjective.
- In many cases, the scalar vague noun phrases relate to time and space, as in “a long-running debate” or “large interior sites”.
- 24% of the scalar vague noun phrases are events.
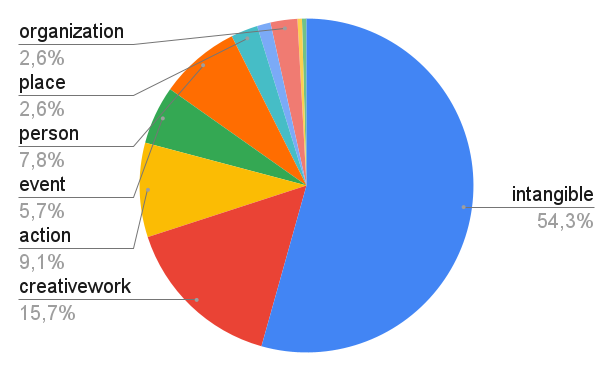
- Quantitative vagueness is the most frequent type of vagueness, affecting 14% of the noun phrases.
- Plural noun phrases are more likely to be quantitatively vague than any other type of vagueness (44% of plural noun phrases are quantitatively vague).
- Quantitative vagueness concerns almost exclusively (97%) plural noun phrases.
- 67% of quantitative vagueness is made up by undetermined nouns.
- 19% of quantitatively vague noun phrases come with a (vague) quantity, such as “several”, “many”, or “few”.
- Mass nouns are not so much represented (7% of the quantitatively vague phrases), because they cannot appear in numbers.
- Creative works are very often quantitatively vague (26%).
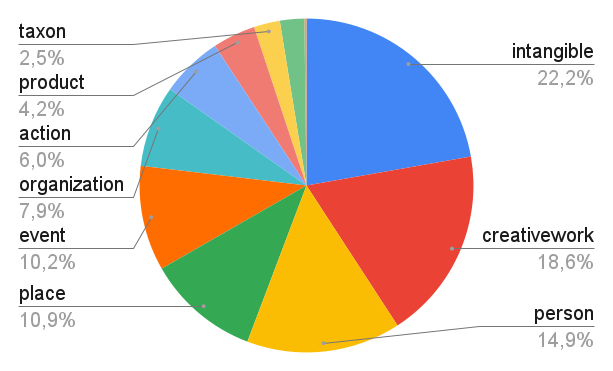
- 9% of the noun phrases are subjectively vague.
- Half of the subjectively vague phrases concern intangible objects like “sufficient interest”, “his greatest fame” or “the sport’s popularity”.
- Creative works are also quite frequently subjectively vague (at 16%).
- Subjective vagueness comes in noun phrases with adjectives in 62% of the cases.
- Mass nouns are often subjectively vague (31%).
Detecting vagueness
Most methods to detect vagueness rely on classifiers trained on domain specific datasets:
- Alexopoulos and Pavlopoulos (2014) detect vague definitions in an ontology about citations.
- [Rosadini et al. (2017)][Rosadini et al. (2017)] study quality defects in requirement specifications in the railway domain.
- [Reidenberg et al. (2016)][Reidenberg et al. (2016)] and [Liu et al. (2016)][Liu et al. (2016)] study vagueness in the context of privacy policies.
- [Lebanoff and Liu (2018)][Lebanoff and Liu (2018)] asked crowd workers to annotate phrases in privacy policies by vagueness scores between 1 and 5.
Modeling and reasoning with vagueness
Several approaches have been proposed to model and reason with vagueness.
- For the quantitative vagueness, there are generalized quantifiers (GQ) that are generalizations of the standard first-order logic quantifiers ∀ and ∃. GQs allow modeling and reasoning with sentences such as “More than half of John’s arrows hit the target”. Fragments of first-order logic or modal logic can be extended with such quantifiers. Interestingly, validity is decidable for most of these extensions, which distinguishes them from First Order Logic.
As an example, let us consider the sentence “Most cities in Taiwan are major cities” and the generalized quantifier $Q_{Most}$, which stands for “most” and means that |A ∩ B| > |A − B| is true with A being the set of Taiwanese cities and B the set of major Taiwanese cities. Then, $Q_{Most}$ can be embedded into description logic with a new operator $\rightarrow_{Q_{Most}}$ [Tu and Madnick, 1997], and the quantitative vagueness in “Most cities in Taiwan are major cities” can be expressed as: $$City(x)\wedge Located(x, Taiwan)\rightarrow_{Q_{Most}} is(x,Major)$$
- For the scalar vagueness, there are fuzzy sets and fuzzy logic, and mixed formalisms with fuzzy and description logics.
- For scalar and quantitative vagueness, there is Vagueness Ontology (Alexopoulos et al. (2014) and [Jekjantuk et al. (2016)][Jekjantuk et al. (2016)]). The idea is to annotate vague expressions so that users can use them the intended way.
- For scalar vague adjectives such as “tall” or “heavy”, a Bayesian approach is possible ([Lassiter and Goodman (2017)][Lassiter and Goodman (2017)]).
- [Sentifiers][Sentifiers] can model scalar vague modifiers by mapping them to numerical attributes using word co-occurrence.
What remains to be done
We conducted an experiment on vagueness detection. Using Scikit-Learn, we trained a simple Ridge classifier with built-in cross-validation for multinomial models on our Wikipedia corpus. We obtained an accuracy of 0.78 when classifying noun phrases according to their vagueness type(s), i.e.,scalar, quantitative, subjective or not vague. The result can obviously be improved, yet it is rather good.
What is really needed and more complex is the modeling part:
- Indeed, it requires to integrate several kinds of formalisms such as description logics, generalized quantifiers and fuzzy logic to handle both scalar and quantitative vagueness.
- Moreover, subjective vagueness is much more difficult to deal with. Besides annotating every subjective noun phrases with the person who employed it to obtain a limited type of reasoning, there is no obvious solutions for now.
Additional materials
All data are located in the data directory of our Github repo:
articles: this folder contains the 30 original Wikipedia articles.annotation guideline.md: this file describes the process we followed to annotate the Wikipedia articles.annotations: this folder contains the annotations of articles from thearticlesfolder.stats: this folder contains the stats we computed. You can check both the annotations and the code we used to compute those stats.- The AKBC paper.
The analysis.py script can be executed to compute the stats corresponding to our annotations.
To cite this work
Pierre-Henri Paris, Syrine El Aoud and Fabian M. Suchanek. The Vagueness of Vagueness in Noun Phrases. In 3rd Conference on Automated Knowledge Base Construction (2021).
Acknowledgments
This work was partially funded by the grant ANR-20-CHIA-0012-01 (“NoRDF”).
[Jekjantuk et al. (2016)]: https://ieeexplore.ieee.org/document/7439337 (Lassiter, Daniel, and Noah D. Goodman. “Adjectival vagueness in a Bayesian model of interpretation.” Synthese 194.10 (2017): 3801-3836.) [Lassiter and Goodman (2017)]: https://link.springer.com/article/10.1007/s11229-015-0786-1 [Sentifiers]: https://ieeexplore.ieee.org/abstract/document/9331269 (Setlur, Vidya, and Arathi Kumar. “Sentifiers: Interpreting vague intent modifiers in visual analysis using word co-occurrence and sentiment analysis.” 2020 IEEE Visualization Conference (VIS). IEEE, 2020.) [Rosadini et al. (2017)]: https://link.springer.com/chapter/10.1007/978-3-319-54045-0_24 (Rosadini, Benedetta, et al. “Using NLP to detect requirements defects: An industrial experience in the railway domain.” International Working Conference on Requirements Engineering: Foundation for Software Quality. Springer, Cham, 2017.) [Reidenberg et al. (2016)]: https://www.journals.uchicago.edu/doi/abs/10.1086/688669 (Reidenberg, Joel R., et al. “Ambiguity in privacy policies and the impact of regulation.” The Journal of Legal Studies 45.S2 (2016): S163-S190.) [Liu et al. (2016)]: https://www.aaai.org/ocs/index.php/FSS/FSS16/paper/viewPaper/14059 (Liu, Fei, Nicole Lee Fella, and Kexin Liao. “Modeling language vagueness in privacy policies using deep neural networks.” 2016 AAAI Fall Symposium Series. 2016.) [Lebanoff and Liu (2018)]: https://arxiv.org/abs/1808.06219 (Lebanoff, Logan, and Fei Liu. “Automatic detection of vague words and sentences in privacy policies.” arXiv preprint arXiv:1808.06219 (2018).)
Pierre-Henri Paris
Associate Professor in Artificial Intelligence
My research interests include Knowlegde Graphs, Information Extraction, and NLP.