Collecter des informations sur le Web

Pierre-Henri Paris - Juin 2023
Avec des éléments de Jean-Claude Moissinac
Introduction
Objectif
Sur le Web :
- Des milliards de pages
- Des services de données
- Des fichiers (PDF, txt, …)
Comment obtenir des données du Web ?
Le Web Crawling
Définition: Le Web Crawling est le processus par lequel un programme ou un “robot” automatique parcourt systématiquement les sites Web pour en collecter les données.
Utilisations courantes :
- moteurs de recherche pour indexer le contenu du Web,
- surveillance des modifications de sites Web,
- le suivi des liens pour la construction de graphes du Web,
- la collecte de données pour l’analyse de données à grande échelle,
- deep learning.
Le Web Scraping
Définition: Le Web Scraping est le processus d’extraction de données spécifiques d’un site Web.
Utilisations courantes: collecte de données dans le domaine du data mining (analyse plus approfondie).
- la veille concurrentielle,
- l’agrégation de données de médias sociaux,
- le recrutement,
- la collecte de données de produits pour la comparaison de prix,
- et bien d’autres cas d’utilisation.
Différences entre Web Crawling et Web Scraping
Portée
- Web crawling $\rightarrow$ indexer un site complet (ou le Web)
- Web scraping $\rightarrow$ extraire des informations spécifiques
Différences entre Web Crawling et Web Scraping
Profondeur
- Web crawling $\rightarrow$ suit les liens de page en page
- Web scraping $\rightarrow$ fonctionne au niveau de l’élément
Différences entre Web Crawling et Web Scraping
Outils
- Web crawling $\rightarrow$ outils complexes (navigation + quantité de données)
- Web scraping $\rightarrow$ plus simples (extraction de données HTML)
Le choix entre Web Crawling et Web Scraping
Web Crawling
- Idéal pour indexer ou naviguer à travers un site web entier
- Utile pour suivre les liens et découvrir du contenu
- Préféré pour les moteurs de recherche ou pour créer une copie d'un site web
Web Scraping
- Idéal pour extraire des informations spécifiques d'une ou plusieurs pages
- Préféré pour des tâches comme l'agrégation de données
Sources de données du Web
Types de sources de données sur le Web
- Web classique (voir cours HTML)
- Pages dynamiques
- Dont négociation de contenu
- Autres types de contenus (voir cours NLP)
- PDF, Gif, fichiers txt…
- Pages Web sémantique (voir prochain cours)
- APIs, Web Services
- OpenData
Web Services
- Logiciel accessible via HTTP/HTTPS.
- Utilise des protocoles comme GraphQL, SOAP ou REST.
- Emploie des méthodes standard : GET, POST, PUT, DELETE.
- Formats de données indépendants : XML, JSON.
Avantages des services Web
- Accessible où le Web est disponible.
- Services partagés entre applications.
- Composition de services avancés.
- Profite d’une infrastructure réseau solide.
REST: Representational state transfer
- Style d’architecture pour systèmes distribués, non un protocole ou format.
- Basé sur la thèse de Roy Fielding.
- Principes :
- Utilisation de l’URI pour l’accès au service.
- Exploitation des fonctions HTTP : GET, PUT, POST, DELETE.
- Les codes de statut HTTP
- Fonctionnement sans état.
REST: Fonctionnement sans état
- Pas de stockage d’information entre requêtes.
- Réduit la charge du serveur.
- Facilite le débogage et la répartition de la charge.
Avantages de REST
- Facile à implémenter, particulièrement pour les développeurs web.
- Intégration fluide avec HTTP.
- Utilisation de caches via l’association URL/ressource.
GraphQL
- GraphQL est un langage de requête pour les API
- Il offre une alternative efficace à REST
- Créé par Facebook en 2015, open source
Caractéristiques de GraphQL
- Un seul point de terminaison
- Structure de requête définie par le client
- Permet des requêtes complexes
- Réduit le sur- et sous-chargement de données
OpenData
- Données librement disponibles pour tous.
- Utilisé pour augmenter la transparence et favoriser l’innovation.
- Formats communs : CSV, JSON, XML.
APIs Web
On parle souvent d’API Web pour les services accessibles sur Internet
Exemple de répertoire d’API:
Web Crawling
Le fonctionnement du Web Crawling
Le processus du crawling

Les défis du crawling

- la gestion de la profondeur du crawl,
- l’évitement des pièges tels que les boucles infinies de liens,
- l’adaptation à la dynamique des sites web (modification / suppression de contenu),
- la gestion des politiques de robots.txt,
- et la politesse du crawler (ne pas surcharger les serveurs du site).
Les défis du crawling
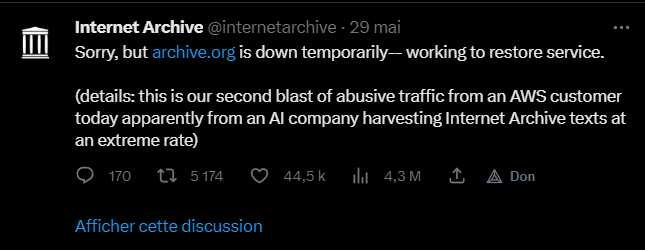
Limiter le parcours
Problème :
- Taille du Web: le Web est infini !
- Pièges à robots, boucles sans fin
- Pages dynamiquement créées
- Garder un focus sur des pages importantes
- Dans un contexte donné
- Par domaines DNS
- Par sujets
- …
Limiter le parcours
Solutions :
- Concentrer l'exploration sur :
- Pages clés selon le contexte (heuristique, IA…) [Abiteboul et al., 2003]
- Domaines DNS spécifiques (ex : même domaine que l'URL initiale)
- Sujets précis via le crawling ciblé [Chakrabarti et al., 1999, Diligenti et al., 2000] [Bruneval, TextMine 2020]
- Contrôler l'exploration à l'intérieur d'un domaine en :
- Limitant la profondeur de visite
- Restreignant le nombre de pages visitées
- Définir des conditions d'arrêt (ex : termes spécifiques ou types de contenus comme PDF ou images)
Bonnes pratiques
Eviter le DOS (Denial Of Service)
Attendre de 100ms à plusieurs secondes avant de solliciter à nouveau un domaine déjà sollicité
Bonnes pratiques
Respecter les exclusions
- Fichier robots.txt à la racine d’un serveur
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xml
Bonnes pratiques
Respecter les exclusions
- Exclusion par meta dans une page
<meta name="ROBOTS" content="NOINDEX, NOFOLLOW">
- Exclusion sur un lien
<a href="mapagesecrete.html" rel="nofollow">
Traitement parallèle
- Délais des réponses réseau
- $\rightarrow$ attente des réponses et
callback
- $\rightarrow$ attente des réponses et
- File d’attente par domaine
- Et réglages associés : délai, parseur, filtres
- Traitements parallèles des requêtes
- Programmation multi-thread
- Entrées/sorties asynchrones
- Option keep-alive (ou HTTP/2) pour diminuer la charge des connexions
- Distribution
- Map-reduce
Eviter les pages visitées : HTTP Timestamping
- Entity tags
- Identificateur unique du document; change si le document change
If-Match
- Modification dates
If-Modified-Since
Souvent fournis pour les contenus statiques
Rarement fournis pour les contenus dynamiques
HTTP Cache-Proxy
Cache‐Control: max‐age=60, private Expires: Tue, 01 Apr 2008 13:25:55 GMT
- max-age : délai maximum où un document reste à jour
- Expires : date à laquelle un document sera considéré comme dépassé
- Souvent fourni…
- … Mais avec 0 ou un délai d’expiration très court.
- information de faible portée
- Données meta et autres dans le contenu des pages
Autres informations temporelles
Des fichiers autres que HTML peuvent avoir une information de version et/ou de date
- PDF, documents Open Office, etc.: des metadonnées contiennent des informations de date de création et de dernière modification
- RSS feeds: contiennent des estampilles temporelles fiables
- Images, Sons: EXIF metadata (ou similaire). Pas toujours exploitable
- Sitemaps
Content type negociation
- Navigateur et serveur se comportent différemment en fonction du type de contenu
- Le client peut indiquer les types qu’il préfère
- MIME : image/jpeg, text/plain, text/html, application/xhtml+xml, application/pdf
- Les documents texte et HTML : indication sur le jeu de caractère utilisé
HTTP/1.1 200 OK
Content-Type: text/html;
charset=UTF-8
Client et serveur: identification
- Les clients Web clients et les serveurs peuvent s’identifier avec une chaîne de caractère (protocole HTTP)
- Utile pour servir des contenus différents à différents navigateurs, pour détecter des robots…
- … mais n’importe quel client peut s’annoncer comme étant un autre
User-Agent: Mozilla/5.0 (X11; U; Linux x86_64; fr; rv:1.9.0.3)
Gecko/2008092510 Ubuntu/8.04 (hardy) Firefox/3.0.3
Server: Apache/2.0.59 (Unix) mod_ssl/2.0.59 OpenSSL/0.9.8e
Doublons
- Détecter les doublons ou les presque doublons
- Eviter l’indexation multiple d’un contenu
- Cas trivial: même ressource issue de même URL
- Détection de contenu strictement identique
- Contenus presque identiques
Doublons stricts et hachage
- Détection de contenu strictement identique
- Comparaison par hachage
- Une fonction de hachage est une fonction mathématique transformant un objet numérique en un nombre pseudo-aléatoire de taille fixe
- Par exemple, la fonction de hachage de Horner :
- $H(x) = \sum_{i=0}^{n-1} x_i \cdot a^i \mod p$
Pages très proches
- Distance d’édition (edit distance)
- Compter le nombre d’ajout, suppression, échange pour passer d’une chaîne de caractère à l’autre
- Ne passe pas à l’échelle
- Shingles
Pages très proches
# Sentences:
S = "I like the sun"
T = "the sun I like"
# Shingles:
shingles_S = { "I like", "like the", "the sun" }
shingles_T = { "the sun", "sun I", "I like" }
# Intersection and Union:
I = {"I like", "the sun"}
U = {"I like", "like the", "the sun", "sun I"}
# Jaccard Similarity:
similarity = len(I) / len(U) # 0.5
Tag soup
- De nombreux documents HTML du Web datent d’avant HTML 4.01
- de nombreuses pages Web ne respectent pas strictement un des standards
- Les navigateurs ne respectent pas strictement un des standards
- tag soup !
- Appliquer des heuristiques pour interpréter les pages
Analyse de page
- Du très empirique…
- fragile dans le temps si la page évolue
- Au très sophistiqué
- Règles d’analyse
- Analyses linguistiques ou sémantiques
- Apprentissage
- Cas particuliers
- Recherche de suites de mots
- Recherche d’un “motif” à partir de regex
L’éthique et la légalité
Considérations éthiques du Web Scraping et du Web Crawling
- Privacy
- Respect des conditions d’utilisation
- Intégrité des données
Légalité du Web Scraping et du Web Crawling
- Loi sur la fraude et l’abus informatiques (CFAA aux États-Unis)
- Règlement général sur la protection des données (RGPD en Europe)
- Lois sur le droit d’auteur
Licences
Jungle complexe :
- Licences propriétaires
- Licence de marque commerciale
- Licence open source
- Avec copyleft
- Licence Art Libre, Licence CeCILL, CC-BY-SA, GFDL, GPL, LGPL, ODbL
- Sans copyleft
- Licence BSD, Licence CC-BY, Licence X11
- Avec copyleft
LinkedIn vs hiQ Labs
- hiQ Labs collectaient des données en grattant les profils publics de LinkedIn.
- hiQ Labs a déposé une plainte en 2017.
- Le tribunal a conclu que hiQ avait “probablement raison”.
- La 9ème cour d’appel des États-Unis a confirmé l’injonction de hiQ en septembre 2019.

VS

Les outils de Web Crawling
Outils de Web Crawling
Scrapy
- Framework de crawling open-source en Python
- Nombreuses fonctionnalités
- Démo
Scrapy
Avantages :
- Rapide et efficace pour récupérer des données.
- Parallélisme (plusieurs URL en même temps).
- Gérer les requêtes HTTP asynchrones.
- Gestion des cookies et des sessions.
- Respect des règles de robots.txt.
Inconvénients :
- Courbe d’apprentissage.
- Complexe pour des projets simples.
Outils de Web Crawling
BeautifulSoup
- Bibliothèque Python qui est utilisée pour parser le HTML et le XML.
- Arbre de parsing à partir de la page.
- Extraction de données.
- Démo
BeautifulSoup
Avantages :
- Facile à utiliser.
- Excellent pour le parsing de HTML et de XML.
- Méthodes simples pour naviguer, rechercher et modifier l’arbre de parsing.
Inconvénients :
- Ne télécharge pas les pages web.
- Lent.
Outils de Web Crawling
Selenium
- Tester les applications web
- Interagir avec les pages web qui nécessitent du JavaScript
- Démo
Selenium
Avantages :
- Interagir avec les pages web (JavaScript).
- Imiter le comportement humain.
Inconvénients :
- Plus lent que Scrapy et BeautifulSoup.
- Nécessite plus de ressources (navigateur).
Outils de Web Crawling
Autres outils notables
- Puppeteer (une bibliothèque Node.js pour contrôler les navigateurs Chrome ou Chromium),
- Cheerio (utilisé pour le scraping côté serveur),
- PyQuery (une interface Python pour analyser le HTML et le XML),
- Heritrix (utilisé par l’Internet Archive), Nutch (un projet open-source d’Apache), et Crawly (un crawler Elixir pour le scraping à grande échelle).
Comparaison des outils de Crawling et de Scraping
Avantages et inconvénients des outils courants
| Outil | Avantages | Inconvénients |
|---|---|---|
| BeautifulSoup | Facile à utiliser | Ne gère pas le JavaScript |
| Selenium | Peut gérer le JavaScript | Plus lent |
| Scrapy | Puissant et flexible | Courbe d’apprentissage plus raide |
Exemples et études de cas
Exemples de Web Crawling
Exemple 1: Googlebots et l’indexation du Web
- Exploration classique
- Tout type de contenu
- Mise à jour constante de l’index de Google
- Respecte les politiques de robots.txt
- PageRank (voir cours Moteurs de recherche)
Exemples de Web Crawling
Exemple 2: Le projet Common Crawl
- Projet à but non lucratif
- Crawler et à indexer le Web pour le rendre accessible au public.
- Le but est de démocratiser l’accès aux données du Web, en permettant à n’importe qui d’accéder et d’utiliser cet ensemble massif de données.
- Données stockées sur Amazon S3.
Le Web Crawling de Common Crawl
- Robots d’exploration similaires à ceux de Googlebot.
- Respecte les politiques des fichiers robots.txt.
- Données = HTML brut + métadonnées + liens sortants.
Exemples de Web Crawling
Exemple 3: Crawling pour l’analyse du sentiment
- l’opinion publique sur une marque ou un produit,
- les tendances des sentiments sur des sujets d’actualité,
- ou les préférences des utilisateurs en matière de produits ou de services.
Exemples de Web Crawling
Exemple 4: Projet Alexandria
- Plongements de tous les articles sur arXiv
- Titres et résumés seulement pour le moment
- Volonté d’étendre à une grande partie du Web

Conclusion
Sources de données du Web
- Types de sources : Web classique, Web sémantique, APIs/Web Services, OpenData
- Web Services : Accessible via HTTP/HTTPS, protocoles: GraphQL, SOAP, REST
- REST : Architecture pour systèmes distribués, principes: URI, HTTP, sans état
- GraphQL : Langage de requête pour API, point de terminaison unique, requêtes complexes
- OpenData : Données librement accessibles, transparence, innovation
Web Crawling vs Web Scraping
- Web Crawling : Robot automatique, parcours systématique des sites Web
- Web Scraping : Extraction de données spécifiques d’un site Web
- Différences : Portée, Profondeur, Outils
- Choix : Web Crawling pour indexer, Web Scraping pour extraire
Résumé Web Crawling
- Processus : Seeds -> Hyperliens -> Répéter
- Défis : Extraction, Performance, Politique robots
- Limitation : Pages clés, Domaines, Crawling ciblé
- Pratiques : Éviter DOS, Respecter exclusions
- Parallélisme & Distribution : Asynchronie, Map-reduce
- HTTP : Timestamping, Cache-Proxy
- Doublons : Hachage, Edit Distance, Shingles
- Analyse : Heuristiques, Linguistique, Regex
Ethique et légalité
- Ethique : Privacy, Conditions d’utilisation, Intégrité des données
- Légalité : CFAA (US), RGPD (EU), Droit d’auteur
- Licences : Propriétaires, Marque commerciale, Open source (copyleft/non-copyleft)
- Cas : LinkedIn vs hiQ Labs
Outils de Web Crawling
- Scrapy : Open-source, parallélisme, asynchrone, règles robots.txt, courbe d’apprentissage
- BeautifulSoup : Parsing HTML/XML, extraction de données, ne télécharge pas les pages, lent
- Selenium : Interaction JavaScript, comportement humain, lent, ressource-intensive
- Autres : Puppeteer, Cheerio, PyQuery, Heritrix, Nutch, Crawly
Exemples de Web Crawling
- Googlebot : Indexation du Web, respecte robots.txt, PageRank
- Common Crawl : Projet à but non lucratif, données ouvertes, stockage Amazon S3
- Analyse du sentiment : Opinion publique, tendances des sentiments, préférences des utilisateurs
- Alexandria : Plongements des articles ArXiv, projets futurs
Ressources supplémentaires
Livres
- “Web Scraping with Python: A Comprehensive Guide” par Ryan Mitchell.
- “Learning Scrapy” par Dimitris Kouzis - Loukas.
- “Python Web Scraping - Second Edition” par Katharine Jarmul et Richard Lawson.
Cours en ligne
- “Web Scraping and API Fundamentals in Python” sur Udemy.
- “Scrapy: Powerful Web Scraping & Crawling with Python” sur Udemy.
- “Web Scraping in Python” sur DataCamp.
Autres ressources
- Les documentations de Scrapy, BeautifulSoup, Puppeteer
- Des blogs ou sites comme Real Python
- Les forums de discussion en ligne, comme Stack Overflow
Contacts et informations supplémentaires
Si vous avez des questions ou des commentaires, n’hésitez pas à me contacter :
pierre[dash]henri[dot]paris[at]telecom[dash]paris[dot].fr