Data warehouse I
Week 2
Multi-dimensional Model
Introduction to Multi-dimensional Model
A data structure optimized for data analysis
- Purpose: Enable complex analytical and ad-hoc queries with rapid execution time
- Key components: dimensions, measures, facts
Dimensions
Descriptive attributes by which facts are analyzed
Examples: time, product, customer, location
- Dimensions are tables containing:
- Attributes: Descriptive properties of a dimension
- product name, color, size
- Hierarchies: Logical structures within a dimension that support different levels of
granularity
- Example: Year > Quarter > Month > Day
Measures
Numerical facts to be analyzed
- Types of measures:
- Additive: Can be summed across all dimensions
- Semi-additive: Can be summed across some dimensions
- Non-additive: Cannot be summed meaningfully
- Derived measures and calculated members
+----------------------------+
| Sales_Fact |
+----------------------------+
| Customer_ID (FK) | +------------------------+
| Product_ID (FK) |---->| Customer_Dimension |
| Time_ID (FK) | |------------------------|
| Quantity_Sold (Measure) | | Customer_ID (PK) |
| Sales_Amount (Measure) | | Customer_Name |
+----------------------------+ +------------------------+
|
v
+----------------------------+
| Time_Dimension |
+----------------------------+
| Time_ID (PK) |
| Year |
| Month |
+----------------------------+
Facts
Collection of related data items, consisting of measures and context
- Types of fact tables:
- Transaction fact tables
- Periodic snapshot fact tables
- Accumulating snapshot fact tables
- Granularity of facts
- Relationship between facts and dimensions
The Cube Concept
Multi-dimensional representation of data
- Visualizing multi-dimensional data
- Basic operations:
- Slicing
- Dicing
- Pivoting


Benefits of Multi-dimensional Model
- Intuitive data representation
- Efficient query performance
- Flexibility in analysis
Multi-dimensional vs. Relational Model
| Aspect | Relational Model | Multi-dimensional Model |
|---|---|---|
| Primary Purpose | Operational processing (OLTP) | Analytical processing (OLAP) |
| Data Structure | Normalized tables | Denormalized, star or snowflake schema |
| Optimization | For data insertion and updates | For complex queries and aggregations |
| Query Complexity | Simple, predefined queries | Complex, ad-hoc queries |
| Data Redundancy | Minimized | Accepted for performance |
| Time Dimension | Usually represents current state | Historical data is a key aspect |
| Data Volume | Typically smaller | Usually much larger |
In-Class Exercise
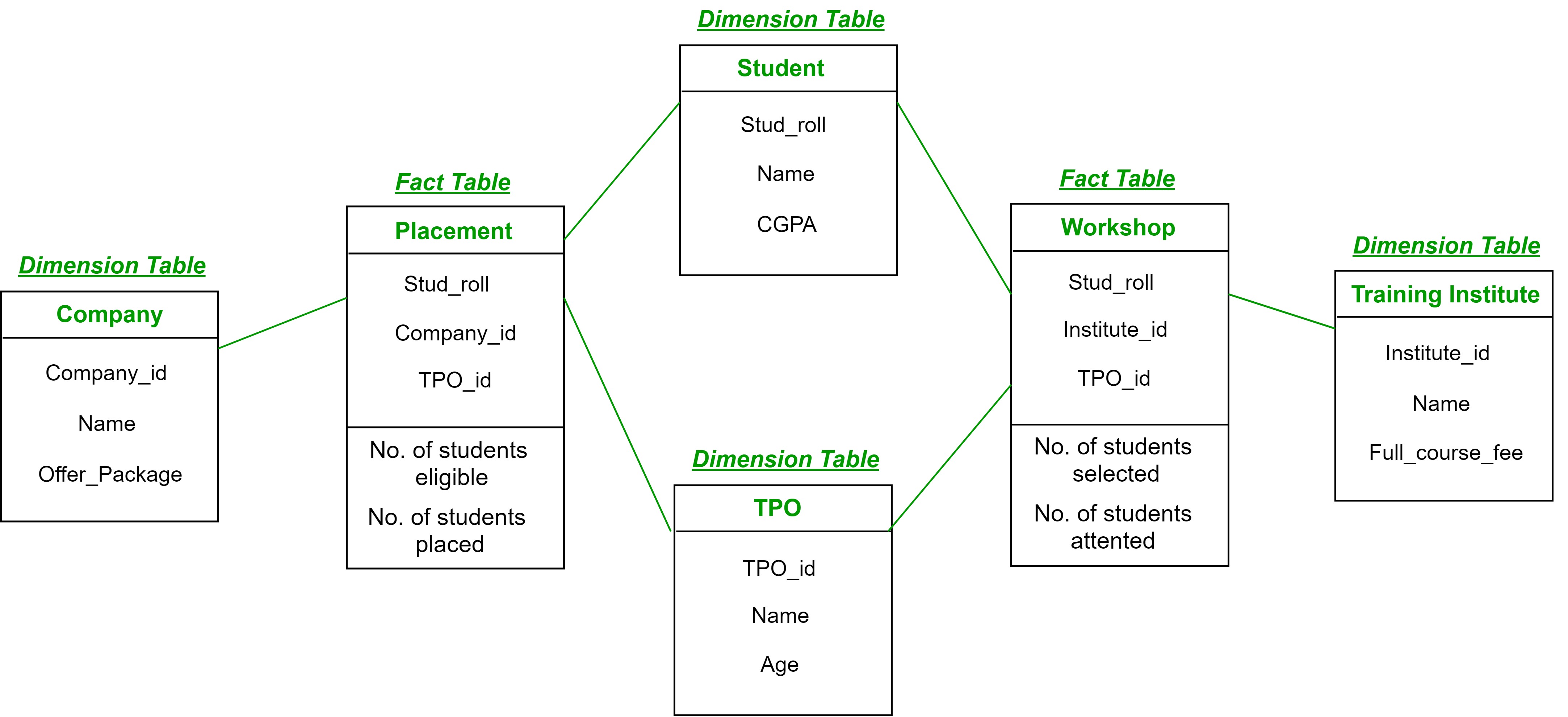
A retail store chain tracks its sales data to analyze business performance. The store collects the following information for each sale:
- Product Information:
Product name, Product category (e.g., electronics, clothing), Price - Customer Information:
Customer ID, Customer age group (e.g., 18-25, 26-35), Gender
- Store Information:
Store location (city), Store region (e.g., North, South) - Sales Information:
Sale date, Quantity sold, Total sales amount (Quantity sold * Price)
Task:
- Identify the Dimensions (descriptive attributes)
- Identify the Measures (quantitative values)
- Define the Fact Table (the main business event and associated facts)
Data Warehouse Architecture and Components
Source Systems
- Types of source systems:
- OLTP databases
- Flat files
- External data sources
- Challenges in data extraction
- Data quality issues
- Heterogeneous data formats
- Data volume and extraction frequency
ETL Process
Extract, Transform, Load- Extract: Collect data from source systems (databases, flat files, etc.)
- Transform: Cleanse, filter, aggregate, and standardize the data
- Load: Move transformed data into the data warehouse or data marts
- Challenges in ETL: Handling large volumes, ensuring data consistency
Data Staging Area
- Purpose and functions
- Temporary storage for extracted data
- Area for data transformation and cleansing
- Improves overall data warehouse performance
- ETL processes in staging area:
- Data extraction
- Data cleansing
- Data transformation
Integration Layer
- Purpose: Consolidate and standardize data from different sources
- Data harmonization and application of business rules
- Prepares data for loading into the core data warehouse
Data Staging Area vs. Integration Layer
| Aspect | Data Staging Area | Integration Layer |
|---|---|---|
| Purpose | Temporary workspace for extracting and transforming raw data | Consolidates and integrates data for unified, consistent datasets |
| Functions | Extraction, cleansing, transformation, loading | Data harmonization, applying business logic, consolidation |
| Nature | Temporary data storage | Permanent, integrated data storage |
| Processing Stage | Early stage of ETL process (before transformation is complete) | Post-transformation, ready for querying or further loading |
| Persistence | Short-term; data is usually discarded after loading | Long-term; integrated data is stored for querying |
Core Data Warehouse
- Central repository characteristics
- Integrated data from multiple sources
- Historical and current data
- Optimized for querying and analysis
- Data organization strategies:
- Normalized approach: Reduces data redundancy, suitable for large-scale enterprise data warehouses
- Dimensional approach: Optimized for query performance, suitable for specific business areas
Data Marts
Subset of data warehouse focused on specific business area
- Types:
- Dependent data marts: Derived from the central data warehouse
- Independent data marts: Built directly from source systems
- Relationship with the core data warehouse
- Can serve as a layer between the core warehouse and end-users
- Provides tailored data for specific departments or functions
Metadata Repository
- Types of metadata:
- Business metadata: Definitions, ownership, and usage of data
- Technical metadata: Data structures, ETL mappings, and database schemas
- Operational metadata: ETL job logs, data lineage, and usage statistics
- Importance of metadata management
- Facilitates data governance and compliance
- Improves data understanding and usability
- Aids in impact analysis and change management
Front-end Applications
- Reporting tools
- OLAP tools
- Data mining applications
- Dashboards and scorecards
Architectural Approaches
- Inmon's approach (top-down):
- Enterprise-wide data warehouse: Centralized repository for all organizational data
- Normalized data model: Reduces data redundancy and ensures data integrity
- Kimball's approach (bottom-up):
- Series of integrated data marts: Built incrementally based on business priorities
- Dimensional model: Optimized for query performance and ease of use
- Hybrid approaches
Multi-dimensional Queries: OLAP Operations
Introduction to OLAP
Online Analytical Processing
- Purpose: Enable complex analytical queries and data exploration
- OLAP vs. OLTP:
- Query complexity
- Data volume
- User types
Basic OLAP Operations
- Roll-up (drill-up): Aggregating data to a higher level
- Drill-down: Navigating to more detailed data
- Slice: Selecting a specific dimension value
- Dice: Selecting values from multiple dimensions
- Pivot (rotate): Changing the dimensional orientation
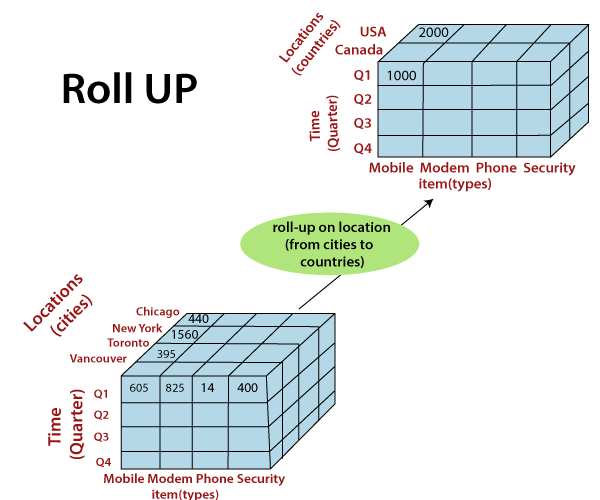
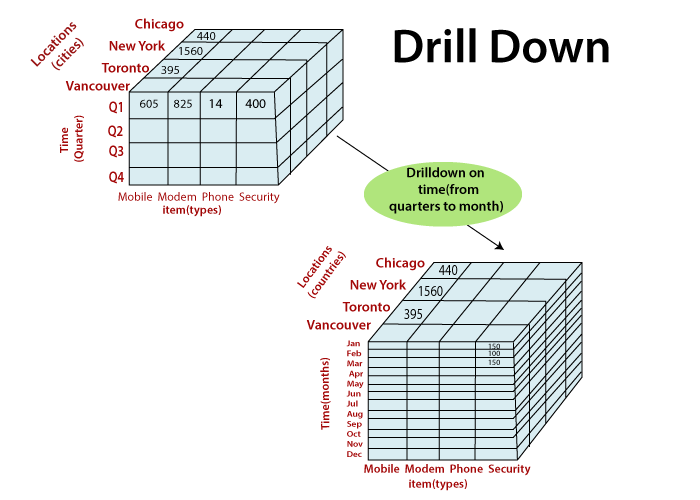
Advanced OLAP Concepts
- Drill-across: Combining data from different fact tables
- Drill-through: Accessing detailed source data
- Ranking and windowing functions
OLAP Schemas
- ROLAP (Relational OLAP): Using relational databases
- MOLAP (Multidimensional OLAP): Using specialized multidimensional databases
- HOLAP (Hybrid OLAP): Combining ROLAP and MOLAP
Querying Multi-dimensional Data
- MDX (Multidimensional Expressions)
-
SELECT { [Measures].[Store Sales] } ON COLUMNS, { [Date].[2002], [Date].[2003] } ON ROWS FROM Sales WHERE ( [Store].[USA].[CA] )
Relational Schemas for Data Warehouses
Star Schema
Fact table surrounded by dimension tables
- Structure: Centralized fact table with foreign keys to dimension tables
- Benefits:
- Simplified queries
- Improved query performance
- Easier to understand and navigate

Snowflake Schema
Extension of star schema with normalized dimensions
- Structure: Dimension tables are normalized into multiple related tables
- Comparison with star schema:
- Reduced data redundancy
- More complex queries
- Potentially slower query performance
- When to use snowflake schema
- When data integrity is a top priority
- When storage space is a concern

Fact Constellation Schema
Multiple fact tables sharing dimension tables
- Structure: Multiple star schemas with shared dimensions
- Use cases and challenges
- Complex business environments
- Maintaining consistency across shared dimensions
- Increased complexity in query design
Choosing the Right Schema
- Factors to consider:
- Query performance requirements
- Data volume
- Maintenance complexity
- Performance implications
- Maintainability and flexibility
Denormalization in DW Schemas
- Purpose: Improve query performance
- Benefits:
- Reduced number of joins
- Faster query execution
- Potential drawbacks:
- Data redundancy
- Increased storage requirements
- More complex data updates
Dimensional Modeling
Introduction to Dimensional Modeling
Technique for designing logical data models for data warehouses
- Purpose: Optimize database structures for analytical queries
- Kimball's approach to dimensional modeling
Steps in Dimensional Modeling
- Choose the business process
- Declare the grain (level of detail)
- Identify the dimensions
- Identify the facts
Fact Tables
- Types of fact tables:
- Transaction fact tables
- Periodic snapshot fact tables
- Accumulating snapshot fact tables
- Selecting appropriate measures
- Handling multiple grains in a single fact table
Dimension Tables
- Role of dimension tables: Provide context to facts
- Slowly Changing Dimensions (SCD):
- Type 1: Overwrite
- Type 2: Add new row
- Type 3: Add new attribute
- Handling hierarchies in dimensions
Handling Complex Scenarios
- Many-to-many relationships:
- Bridge tables
- Factless fact tables
- Handling ragged hierarchies:
- Bridge tables
- Nested sets model
- Dealing with sparse facts:
- Separate fact tables
- Bitmap indexing
Best Practices in Dimensional Modeling
- Choosing the right grain:
- Balance between detail and performance
- Consider business requirements
- Handling multi-valued dimensions:
- Bridge tables
- Flattening the structure
- Ensuring consistency across the enterprise:
- Conformed dimensions
- Standard naming conventions
- Performance considerations:
- Appropriate indexing
- Partitioning strategies
Conclusion and Preview
Recap of Key Points
- Multi-dimensional model concepts
- DW architecture and components
- OLAP operations
- Relational schemas for DWHs
- Dimensional modeling principles
Q&A
Data warehouse I Week 2 © 2024 Pierre-Henri Paris This work is licensed
under CC
BY 4.0